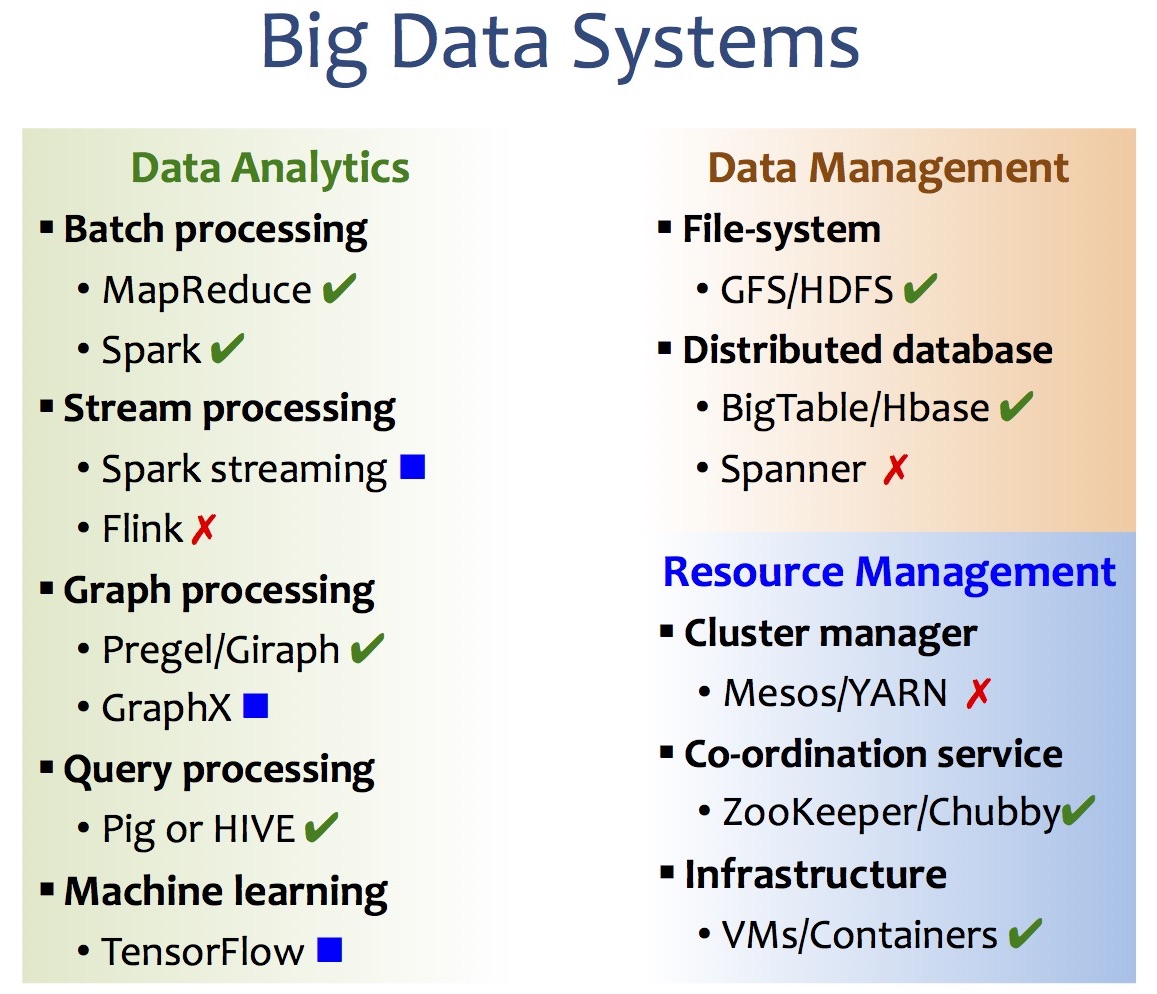
As the foundation of big data technology, big data systems focus on how to process and store large data sets on a distributed environment. They can be categorized according to their function as shown below.
For each new technique, I will concern 3 questions:
- Motivation: Why do we need it or what problem does it address?
- Design principles and architecture: How do it solve the problem?
- Demo: Show me an example.
Data Analytics
MapReduce for batch processing
How can we write parallel application on a computer cluster?
For example, we want to count the frequency of each word in a corpus of documents, such as Wikipedia. For simplicity, we assume the data can be accessed on any machine or node of a cluster.
We need to care about at least 6 design challenges.
- Scheduling: Scheduling is the process of assigning jobs to nodes.
- Parallelization: Jobs are running in a parallel way.
- Synchronization: Some jobs can only start running after other jobs have finished.
- Communication: The master needs to monitor the status of each node and job in real time. The input of a job might rely on the output of another job.
- Fault tolerance: A job should be able to recover from partial failure. If a node fails, the job is reassigned to another node.
- Load balance: Jobs are assigned preferentially to nodes that are not busy
MapReduce is designed for this. MapReduce is a framework for computing large amount of data on a cluster of machines. The runtime library of MapReduce takes care of all these things. Programmers only need to write 2 methods: Map & Reduce.
The runtime system looks like this:
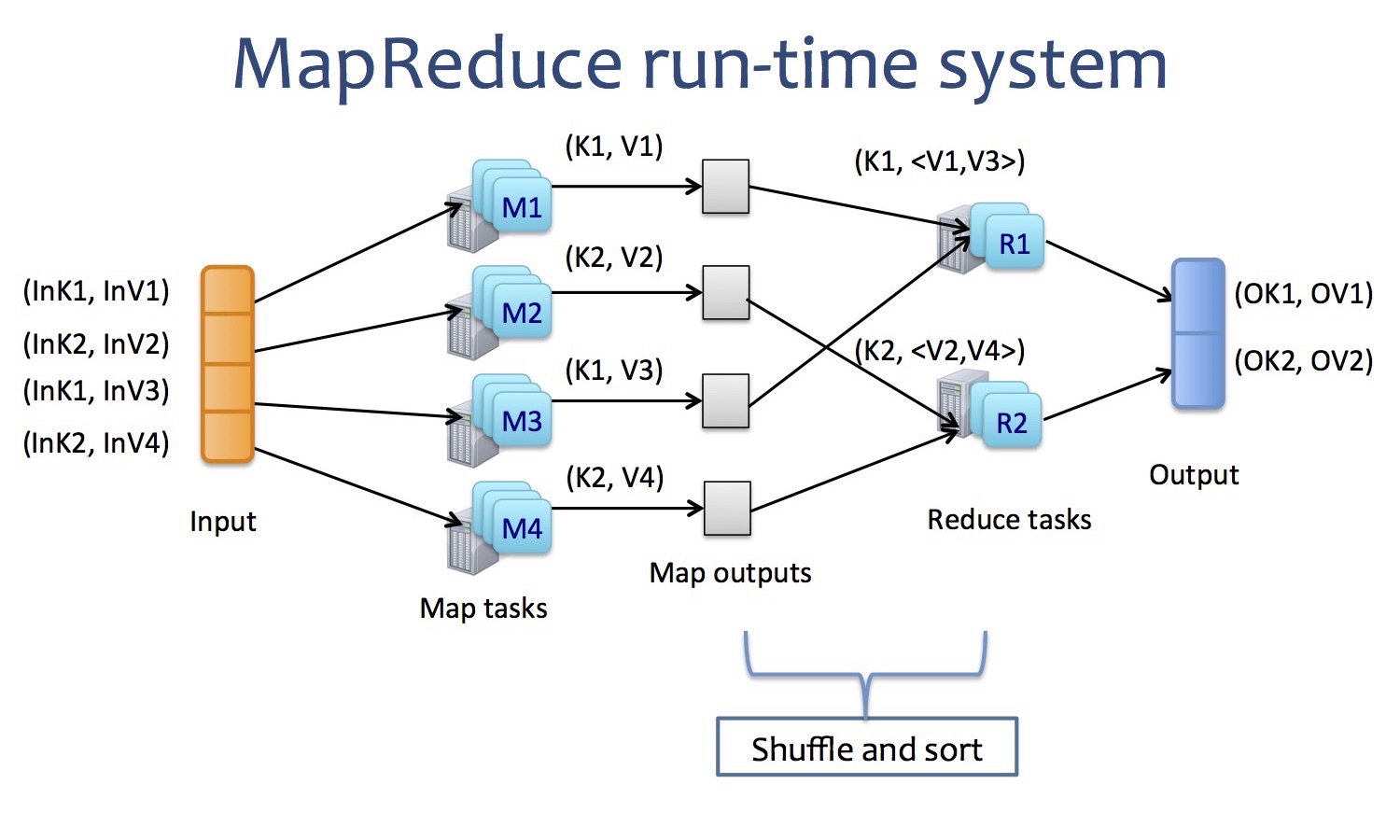
The programming model is as simple as:
Map(key, value) -> (key, value)
Reduce(key, <value>) -> (key, value) # <value> means a list of values
For the classic word-count example, the pseudo code is as follows:
map(str key, str value)
# key: document name
# value: document content
for each word in value:
output(word, "1")
reduce(str key, iterable values)
# key: word
# values: list of counts
count = 0
for each v in values:
count += int(v)
output(str(count))
MapReduce is always run on distributed file system, such as GFS or HDFS. So, the overall software stack of MapReduce look like this:
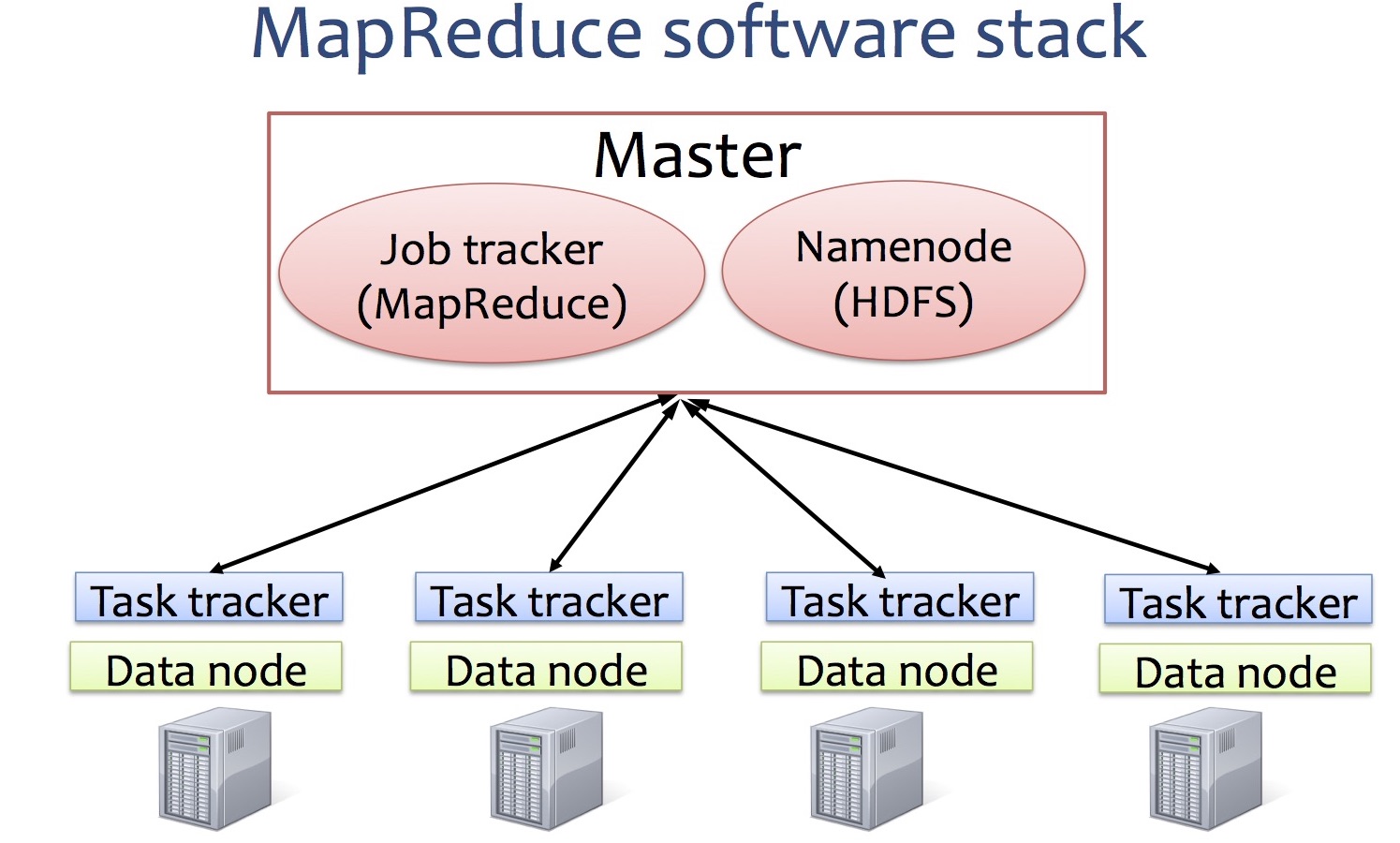
HDFS split large data into multiple parts and store them across nodes.
A jobtracker allocates MapReduce tasks submitted by clients to specific nodes in the cluster, ideally the nodes that have the data. It’s ia single point of failure. A tasktracker is a node in the cluster that accepts tasks (i.e. Map and Reduce operation) from the jobtracker.
The open source implementation of MapReduce is Hadoop which also includes the HDFS. It’s worth noting that the Hadoop streaming enables us to specify external programs as map or reduce function so it’s possible to write map or reduce function in python.
Pig for query processing
MapReduce offers a low-level primitive and requires repeated implementation of common operations such as join, group-by, sort and filter.
Pig is a platform built on top of MapReduce which contains a high-level language for expressing common data analysis tasks for table-like data (e.g. big CSV files).
Programmers no longer need to write MapReduce functions directly but write Pig Latin statements instead. The Pig Latin is a SQL-like language which is compiled into pipelined MapReduce jobs and executed using Hadoop.
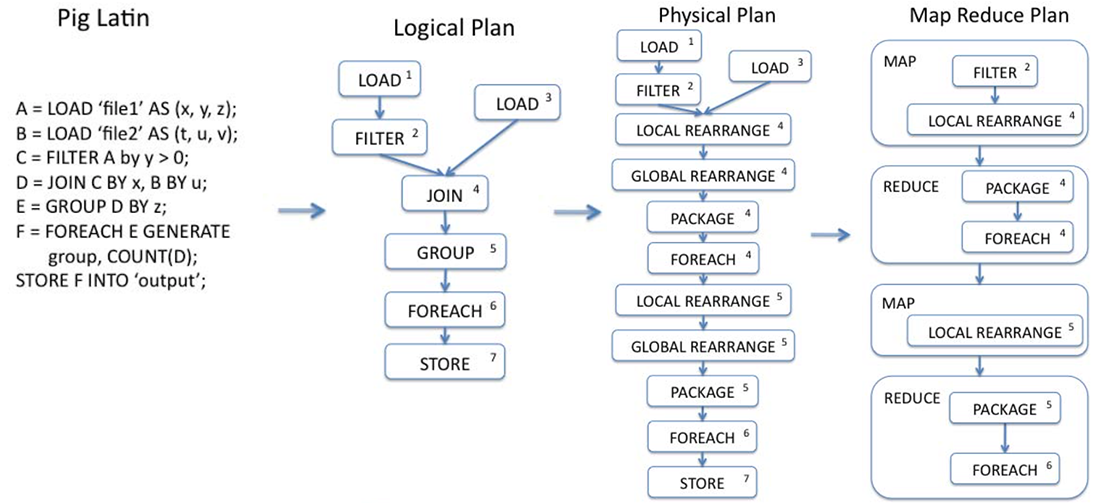
Local rerange corresponds to hash on the output of map task.
Global rerange corresponds to shuffle and sort.
Package corresponds to reduce.
The compilation process consists of Pig Latin script -> logical plan -> physical plan -> MapReduce plan. This staged compilation enables SQL query optimization and MapReduce specific optimization.
Pig also supports user defined function as a way to specify customized processing such as data cleaning.
Pregel/Giraph for graph processing
Here is an example of web graph.

How can we compute the PageRank of each web page? where v is an inbound link to u.
Pregel is a large-scale iterative graph processing system developed by Google. Giraph is the open-source counterpart of Pregel and is currently used at Facebook to analyze social graph formed by users and their connections. Both systems are inspired by Bulk Synchronous Parallel model for distributed computation.
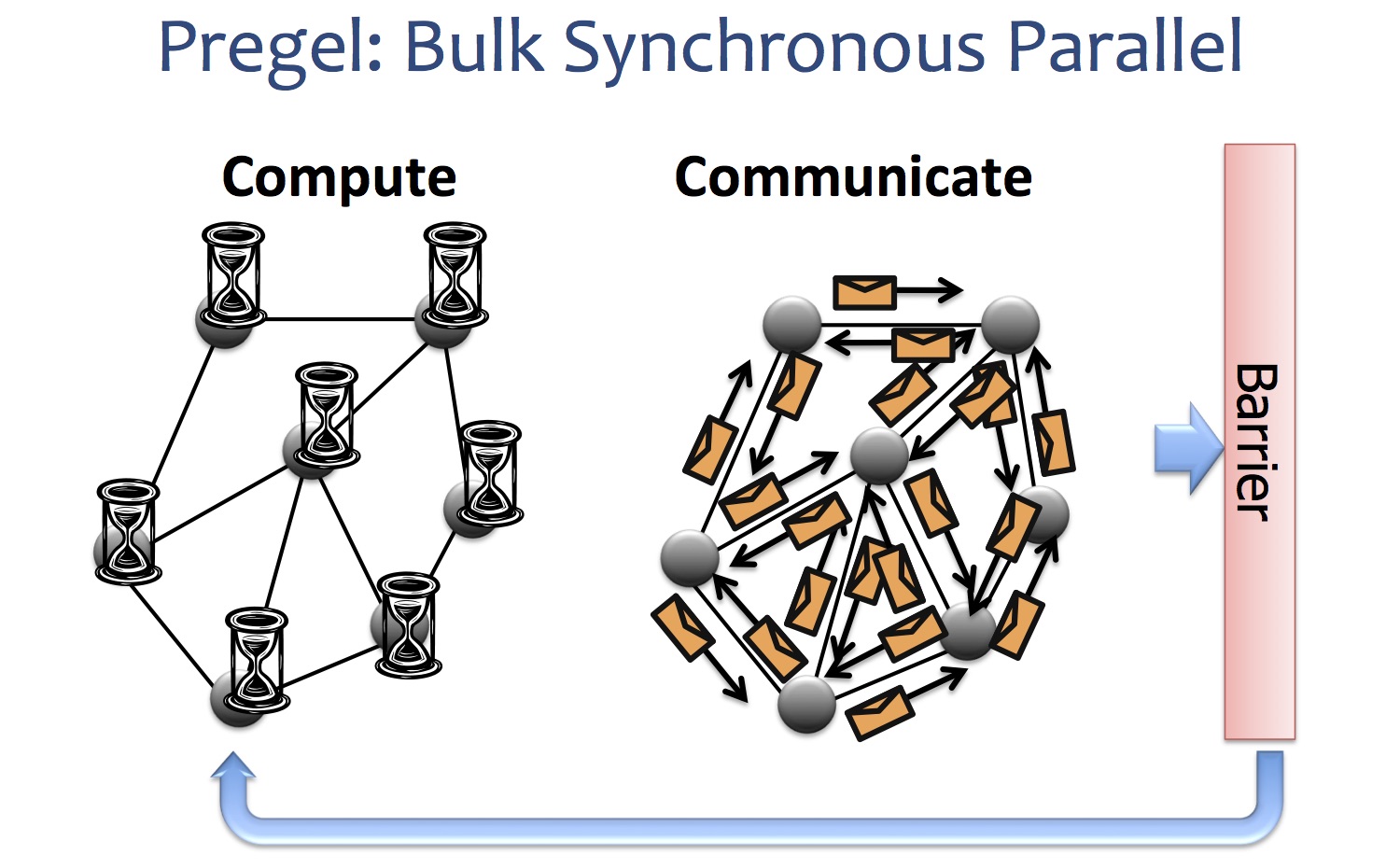
In order to illustrate this programming model, nothing is more straightforward than a simple example. Given a graph where each vertex contains a value, it propogates the largest value to every vertex.
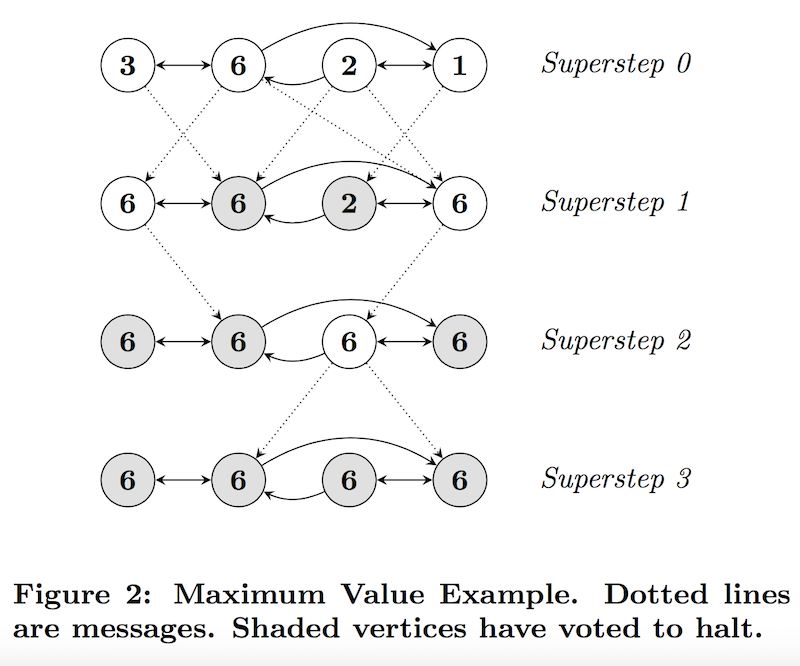
Pregel computation consists of a sequence of iterations, called supersteps. Within each superstep, the vertices compute in parallel and each executes the same user-defined function. A vertex can modify its value, receive messages sent to it, send messages to other vertices by outgoing edges. Communication is from superstep S to superstep S+1. That is, a message sent in current superstep will be received in next superstep. A vertex votes to halt when it has no further work to do. It can be activated again when new messages arrive in a later step.
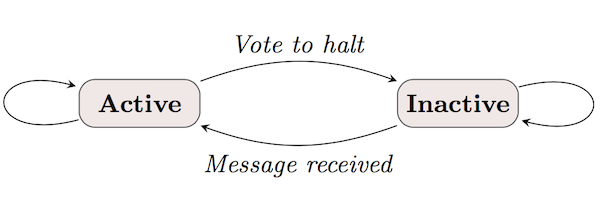
Algorithm terminates when all vertices are simultaneously inactive.
Besides, Pregel also supports additional features:
- combiner: In the example above, the system combines several messages intended for a vertex matters into a single message containing the max value because only the max value matters. In general, combiners help to reduce the number of messages that must be transmitted.
- aggregator: Each vertex provides a value for an aggregator where those values are used to compute some statistics such as min, max.
- topology mutation: The graph topology can also be modified such as removal/addition of edges or vertices.
- fault tolerance: At the beginning of a superstep, master instructs the workers to save the state. If a vertex fails, the partition is reassigned to a new worker and the processing is restarted/resumed from the last checkpoint.
Pregel provides these basic programming APIs:
- Compute(msgs)
- GetValue()
- MutableValue()
- GetOutEdgeIterator()
- SendMsgTo()
- SuperStep()
- voteToHalt()
A simplified implementation of PageRank using Pregel is as follows.
class PageRankVertex: public Vertex<double, void, double> {
public:
virtual void Compute(MessageIterator* msgs) {
if (superstep() == 1) {
*MutableValue() = 1/NumVertices();
}
else {
double sum = 0;
for (;!msgs->Done(); msgs.Next())
sum += msgs->Value();
*MutableValue() = 0.15/NumVertices + 0.85*sum
}
if (superstep() < 30) {
int n = GetOutEdgeIterator().Size();
SendMsgToAllNeighbors(GetValue()/n);
}
else {
VoteToHalt();
}
}
}
Data Management
Google File System (GFS) for big data storage
Distributed file system is required to management big data because single server or disk has limited storage and bandwidth.
Key design requirements for distributed file system:
- Performance: high throughput and low latency
- Concurrence: multiple clients access concurrently
- Reliability: data integrity, consistency and accessible.
- Availability: service is accessible at any given time
- Scalability: support large-scale and growing data
GFS is such a system developed by Google and Hadoop distributed file system (HDFS) is an open source implementation of it.
Interface is similar to familiar file system.
-
hadoop fs -<fs commands> <arguments><fs commands>includes ls, mv, rm, cp, copyFromLocal, copyToLocal etc. -
Programming API is Not POSIX compatible but supports snapshot and record append
The remainder of this subsection will focus on the design aspects of GFS/HDFS.
The basic architecture of GFS is shown below. GFS consists of a single master and multiple chunkservers (datanodes). Master and chunkservers communicate by regularly exchanged HeartBeat messages.
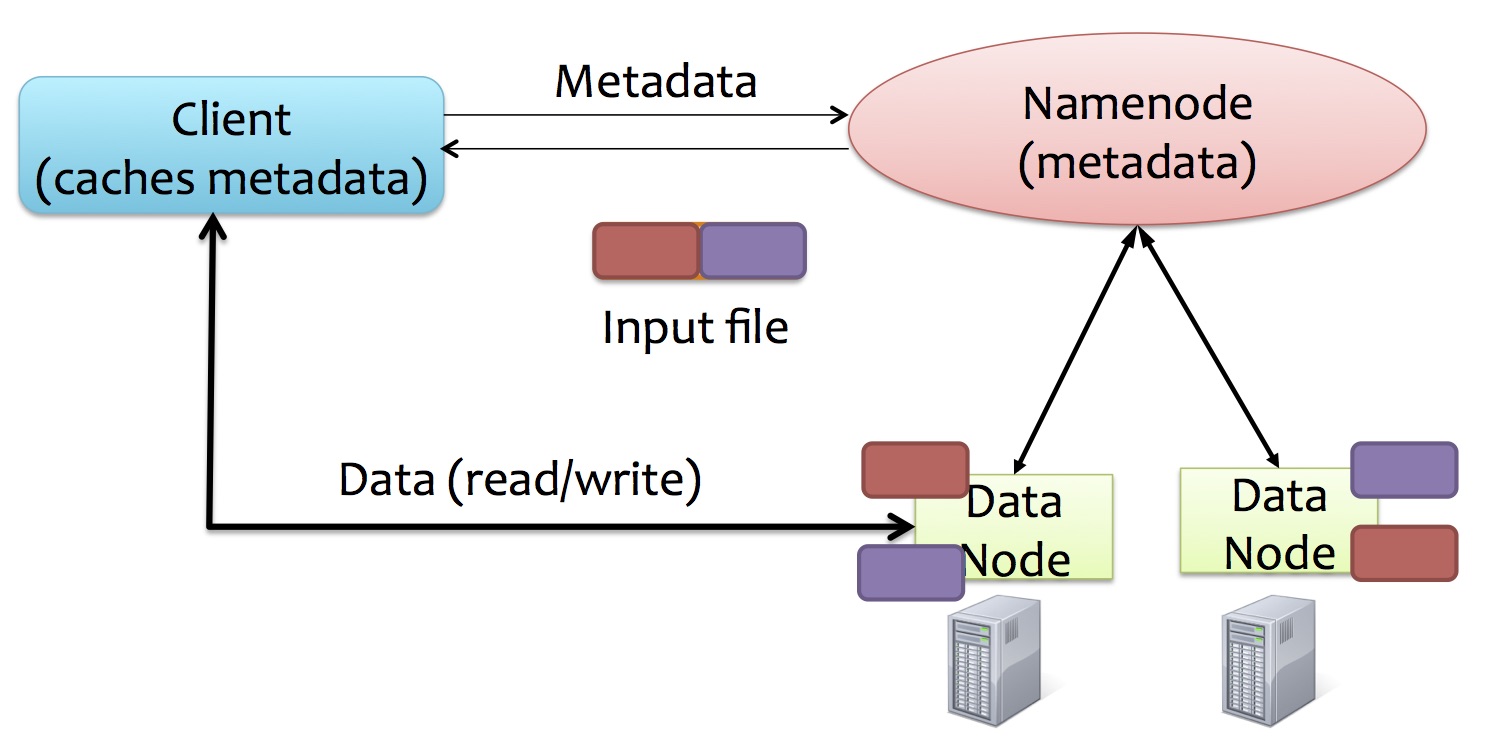
Master
- maintain metadata (kept in memory): mapping from files to chunks, location of replica chunks
- namespace management and locking: use locks over a region of the namespace but still allow operations on other regions to be active
- replica management
- replica placement: when creating a chunk, place the new replica on a chunkserver 1) with low space utilization 2) limit recent creations 3) across racks
- re-replica: when the number of replicas of a chunk falls below a user specified goal
- replica rebalancing/migration: for better space utilization and load balancing
- lease management to maintain a consistent mutation order across replicas
- garbage collection in a lazy mood: regular scan of namespace and erase metadata
- replication (availability)
- checkpoints and operation logs are replicated on multiple machines
- When it fails, a new master recovers by loading from the latest checkpoint and applies log records after that
Chunkserver
- Files are divided into fixed-sized (default: 64MB) chunks stored on chunkservers as normal Linux files
- Each chunk is replicated on multiple (default: 3) chunkservers. (reliability)
- data integrity achieved by checksum
Clients
- look up metadata (chunk location) from master and interact with chunkservers for reading or writing data
- read from one replica
- write is performed by pushing data to all chunk replicas and sending a write request to the primary chunkserver
HDFS only supports Append-only write while GFS also supports updates of a file or chunk. Append operation allows multiple clients to append to a file without extra synchronization between them to deal with race condition. GFS uses lease management to ensure write/mutation operations including both update and append for a given chunk are completed in the same order on all replicas, that is, the replicas will be consistent/identical.
How is consistency achieved in write operation?
- one of the replicas is selected by master as primary and holds the lease
- client pushes data to all replicas which store the data in an internal buffer
- client sends write request to primary replica
- primary replica forwards the request as well as the commit order to all secondary replicas
- each secondary replica applies the mutation in the same serial number order assigned by the primary
- secondaries reply to primary and primary replies to the client
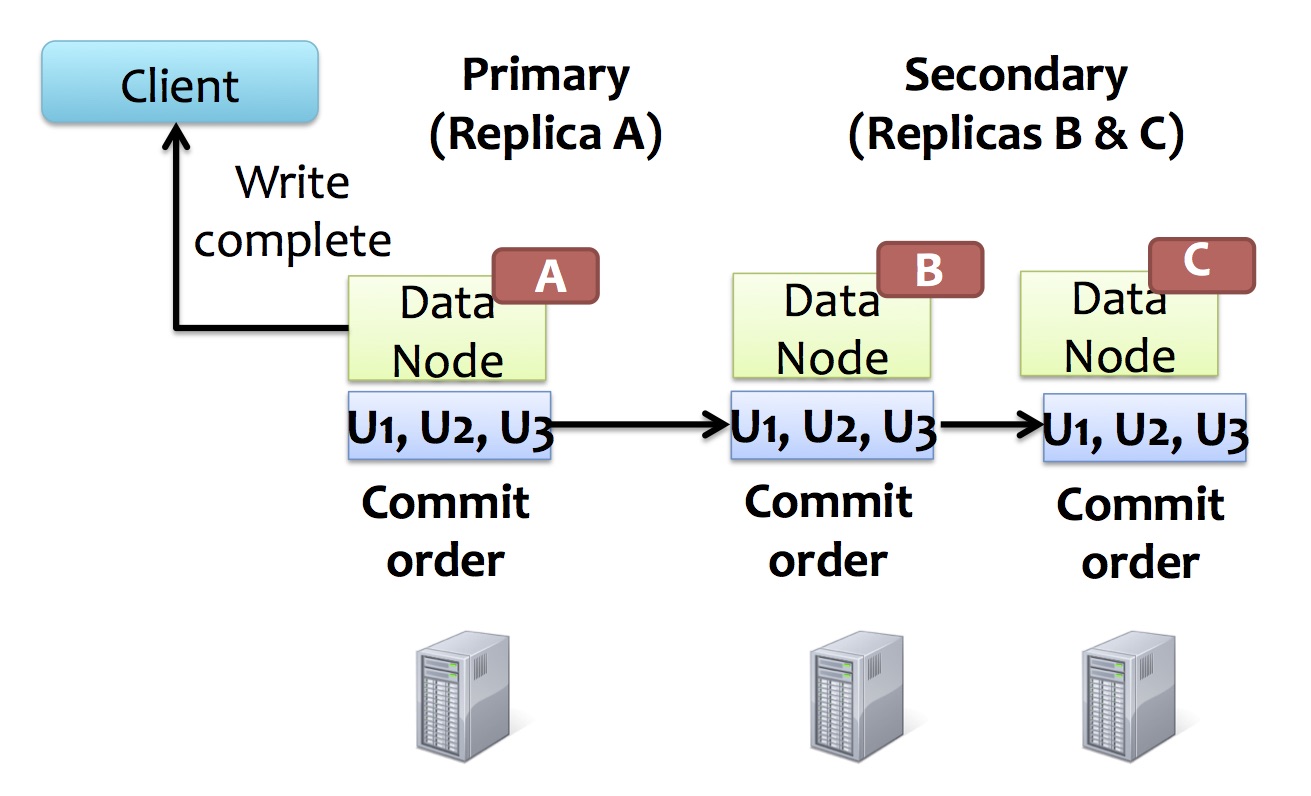
However, write operation is still problematic in a concurrent setting.
- Update operations from different clients can be interleaved and a chunk might end up with fragments from different clients.
- Although a single chunk is consistent, the file might be undefined because different chunks have different primary commit order.
BigTable for structured data
BigTable is a distributed storage system for managing structured data. Many projects at Google store data in BigTable, including web indexing, Google Earth, Google Finance. In short, BigTable is a distributed database for large-scale data. HBase is the equivalent open source project built on top of HDFS.
Comparison of GFS with BigTable:
BigTable
- resembles a database
- data files are stored in GFS. So, replication is handled by underlying GFS
GFS
- designed for unstructured data
- high throughput but not latency sensitive
- sequential reads are dominant
Architecture
A BigTable cluster stores a number of tables. Each table consists of a set of tablets (100-200MB each) corresponding to a row range. Each tablet is served by a tablet server.
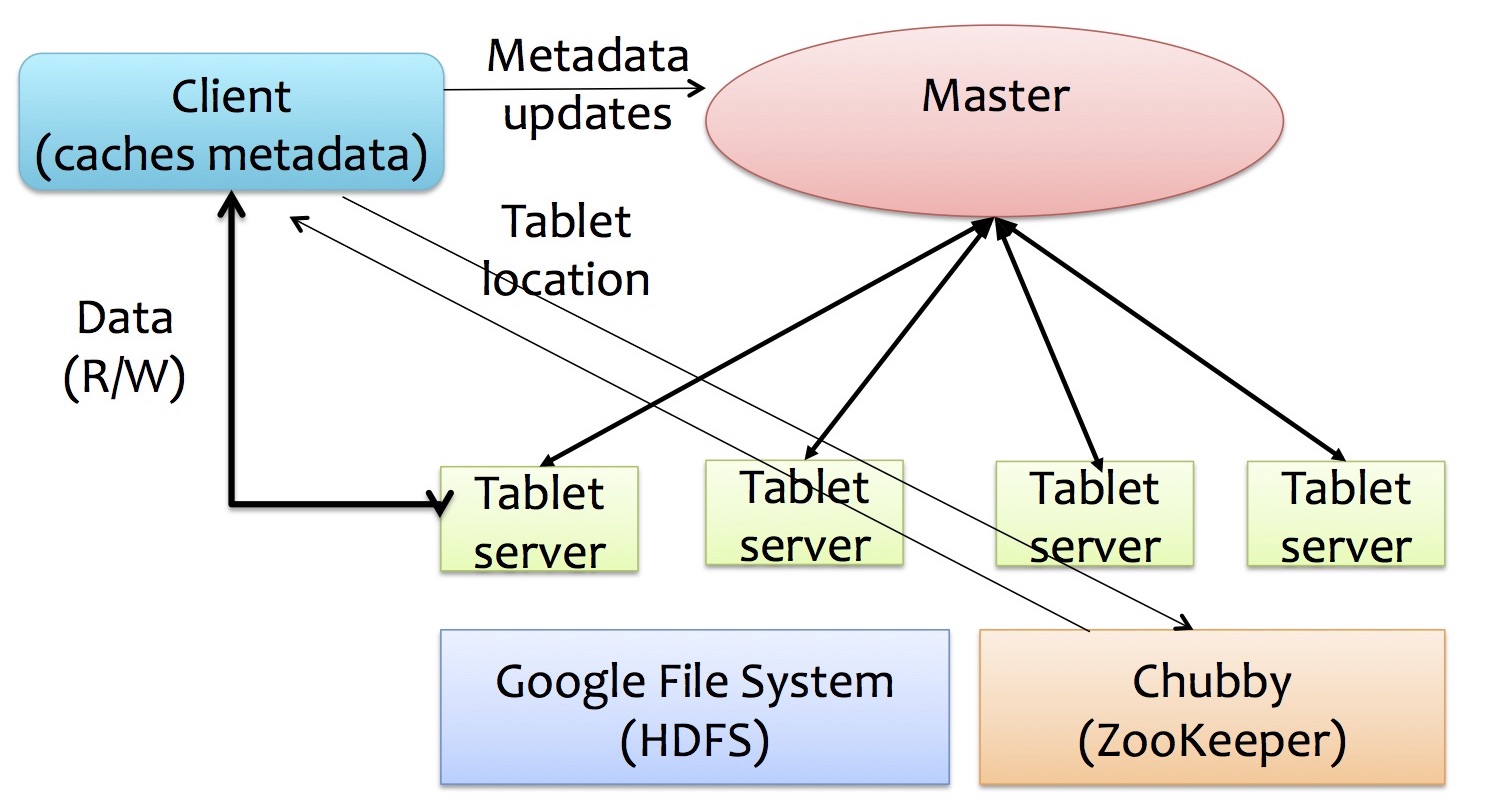
Master
- assign tablets to tablet servers
- detect up/down of tablet server
- garbage collection
- handle schema changes of tables
Tablet Server
- handle read/write to their tablets
- mutation operation is written to the commit log (in disk) and then inserted into memtable (in memory)
- memtable is converted into a SSTable file and written to GFS (in disk) periodically
- read operation is executed on a merged view of a sequence of SSTables and the memtable
- split tablet that grows too large
Chubby (a distributed locking service like ZooKeeper)
- ensure there is only one master, discover tablet servers
- store the location of METADATA table which contains location of all user tablets
- store schema information and access control list of tables
DataModel
A table is indexed by (row:string, column:string, time:int64) → string.
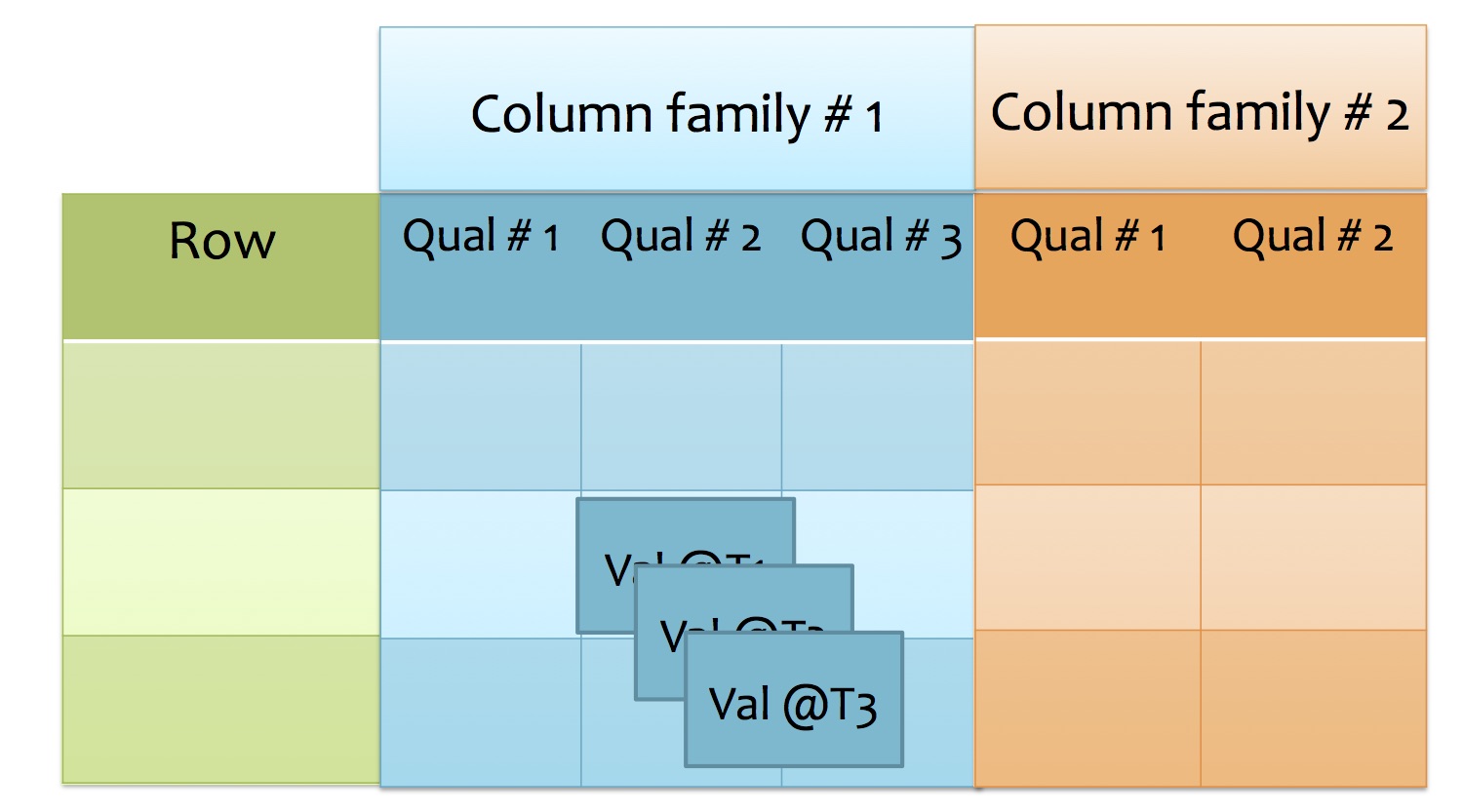
Row
- row key is an arbitrary string
- sorted by lexicographic order
- access to a row is atomic
- doesn't support transaction across rows
Column
- organized in column families. A column family contains a set of columns identified by qualifier
- the format of column key is "family:qualifier"
- column family forms the basic unit of access control
- data in a column family is compressed/stored together
Time
- In order to store different versions of data in a cell, value is versioned based on timestamp (64-bit integer)
- Lookup: return most recent K values or values in some timestamp range
- Garbage: only retain most recent K values or keep until they are older than K seconds
API
- Basci CURD: PUT, DELETE, GET
- Scan
Resource management
Zookeeper for coordination
Zookeeper is a coordination service for distributed application. It exposes common services such as configuration management, group services, naming and synchronization. Implementing these services from scratch is prone to errors such as race condition and dead lock.
Design principles
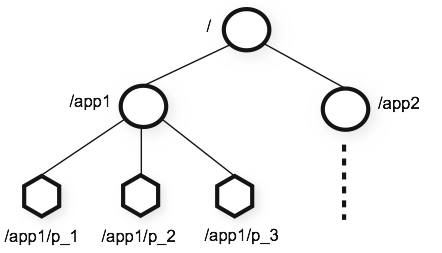
Zookeeper uses a data model organized in a hierarchical namespace styled after the familiar directory tree structure of file system. This hierarchical namespace is useful for allocating subtrees for different applications and setting access permission for them. Each zookeeper data node (znode) can have coordination data (small data used for coordination purposes) associated with it as well as children. Clients can set a watcher on a znode. When the znode changes, the watcher is triggered and the client is notified. This mechanism enables clients to receive timely notification of changes without polling.
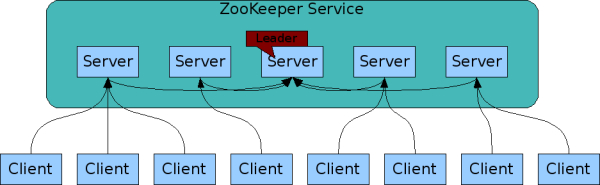
Zookeeper itself is also distributed/replicated. All replicas maintain the same image/copy of state. A client maintains a TCP connection (session) to a single server by which it sends requests, gets response and get watch events. Read requests are served in the local replica which the client connects to. Since the whole data tree is stored in memory, read is especially fast. However, write/update requests are forwarded to a single server (called leader) which in turn commits the change to the rest of servers (called followers) using an atomic broadcast protocol called Zab. Writes are stored in disk before they are applied to the in-memory data tree.
APIs and use cases
Zookeeper only provides minimalistic APIs that can be used to build a wide range of more powerful coordination primitives by the client. Besides, all APIs are wait-free which means there is no blocking and thus no dead-lock.
create(path, data, flags)
delete(path, version)
exists(path, watch)
getData(path, watch)
setData(path, data, version)
getChildren(path, watch)
sync()
version allows clients to track change in znode and execute conditional updates.
flags include
- regular (default): created and deleted by clients explicitly
- ephemeral: deleted automatically when the session which creates it ends
- sequential: monotonically increasing counters appeared in the name
Here are some common use cases
-
configuration management
config └──settingsWatchers are one-time triggers associated with a session. They are unregistered once triggered or the session closes.# workers get config getData('config/settings', true) # admin change the config setData('config/settings', new_settings) # workers are notified of change and get new settings getData('config/settings', true) -
group membership
workers └──worker-1 └──worker-2In distributed system, processes often need to know which other processes are alive.# workers register name in a group create('workers/worker_name', hostinfo, ephemeral) # list group members getChildren('workers/', true) -
leader election
workers └──leader └──worker-1 └──worker-2getData('workers/leader', true) if succeed follow the leader described in the data else # elect itself as leader create('workers/leader', hostname, ephemeral) if succeed act as leader else goto step 1 -
lock
locks └──mutexLock allows mutually exclusive access to critical resources. This simple lock protocol has some problems.create('locks/mutex', data, ephemeral) if succeed # lock acquired do something delete('locks/mutex') else exists('locks/mutex', true) # watch the mutex if succeed: wait until when notified goto step 1- all clients waiting for the same lock are waked up when the lock is released even though only one of them can acquire the lock finally, which might waste a lot of system resource. This phenomenon is called thundering herd.
- clients obtain the lock NOT in the request arrival order
- it only implements exclusive lock (write lock)
-
lock without herding
An optimised lock is as follows:locks └──lock-1 └──lock-2 └──lock-3 └──...The above code can be easily changed to also include read lock.n = create('locks/lock-', data, ephemeral|sequential) C = getChildren('locks', false) if n is the lowest (has smallest sequence number) in C # lock acquired do something delete(n) else p is the znode in C ordered just before n if exists(p, true) wait util notified goto step 2
VMs/Docker
Traditionally, only one Operating System (OS) can run on a PC or Server with matching architecture. By architecture, I mean Instruction Set Architecture (ISA) such as X86 for PC and ARM for mobile devices. It acts as a standard. Both CPU and OS follow a specific architecture.
That is, operating system is tied to underlying hardware.
Virtualization allows an operating system or program to run independently from the underlying hardware. It has many advantages:
- flexibility: A guest OS can run inside a host OS and they can differ in the architecture. So, a Windows OS is possible to run inside MacOS.
- cost-efficient: Multiple virtual machines (VMs) run simultaneously on a single hardware platform, isolated from each other. Virtualization is widely used in cloud computing because server consolidation makes it possible to share computer resource among many services.
- fault tolerance: A virtual machine can be backed up, which makes it easy to migrate and recover from disaster.
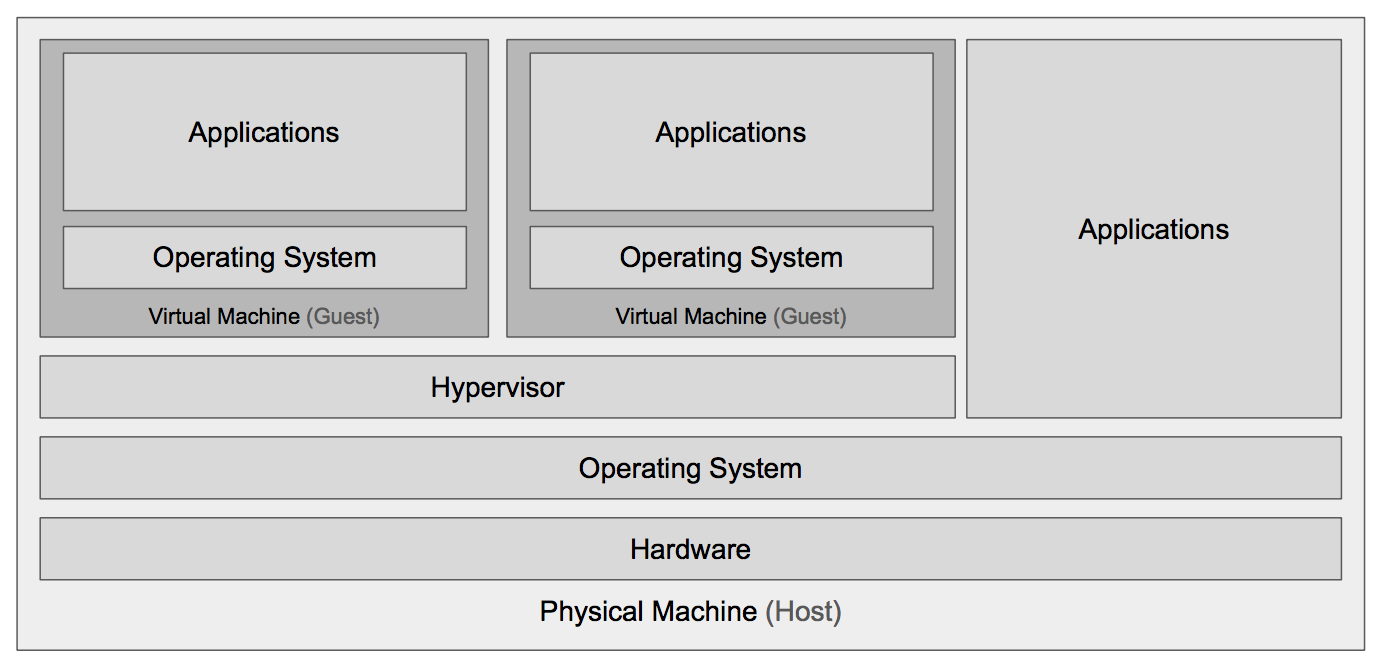
Supervisor is a virtual machine monitor (VMM). There are 2 main types of supervisors. Native supervisor such as XEN, VMServer doesn't require a host OS and runs directly on the host machine or bare metal. Hosted supervisor such as VirtualBox, Qemu runs as an application inside the host operating system.
Virtualization techniques can be categorized into 3 types.
-
Software Emulation: each instruction of the guest OS is emulated (Interpretation) by the supervisor application. It allows cross architecture simulation. Speedup can be achieved by dynamic binary translation.
-
Full system or Hardware Virtualization: most instructions are executed natively on the host CPU. The guest OS is now running as part of VMM in the user mode on the host machine. So, privileged/system instructions can not directly access hardware resource. One solution is to trape-and-emulate which means all privileged operations of guest machine are traped and emulated by the VMM like software emulation. Non-Privileged instructions are still executed natively on the host. A better way is hardware extensions provided by modern CPUs which allow all guest instructions to run natively by providing an isolated view of the processor to virtual machines.
-
ParaVirtualization: Virtualized OS is specifically modified to co-operate with the hypervisor to optimize the resource usage. For example, privileged instructions can be replaced with system calls. Supervisor doesn't need to emulate hardware devices.
Case study - Qemu
Qemu is a hosted hypervisor. As an emulator, Qemu can run OSes or programs made for one machine (e.g. an ARM or MIPS board) on a different machine (e.g. your X86 PC) through software emulation. By using binary translation, it achieves very good performance.
As a virtualizer, combined with backends such as KVM and Xen, Qemu allows full system virtualization by using CPU extensions to achieve near native performance.
Case study - Docker
Docker is a container manager system. Container is a lightweight virtualization technique where a container comprises an application and its dependences and runs as a separate process in the user space of host OS, sharing the kernel with other containers. The difference between container and VM is illustrated below.
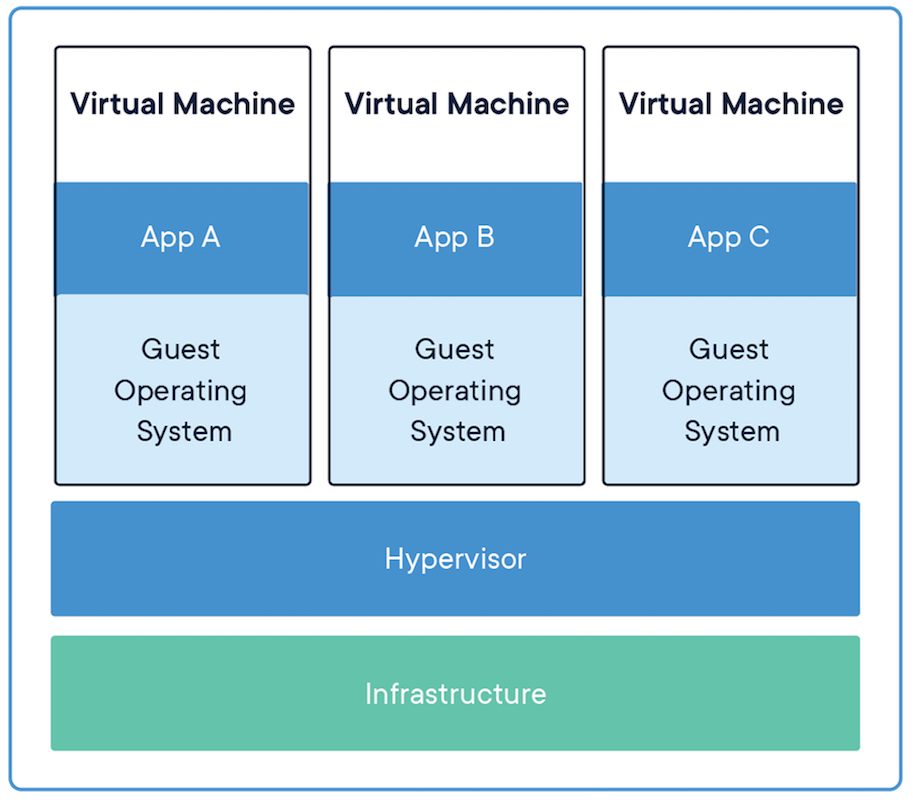
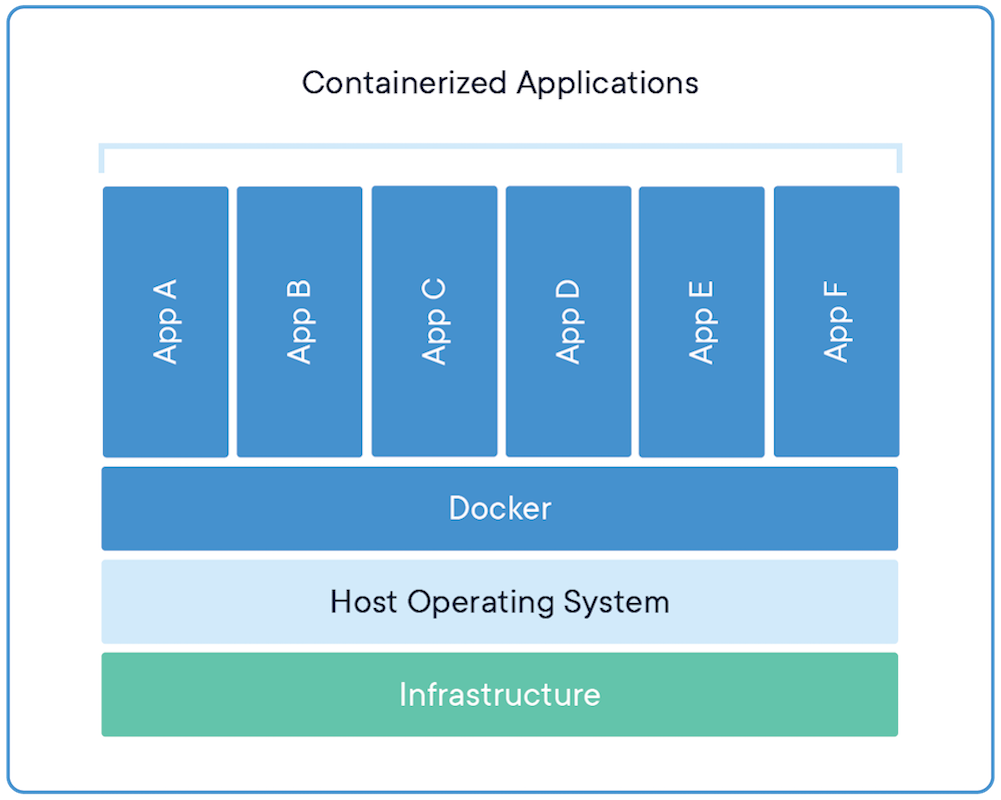
So, the key difference is that a container doesn't have a guest OS. All containers share the same host kernel instead. This also means a container which relies on a linux OS can only run on a linux host. However, they don't have to be the same linux distro. For example, an Ubuntu container can also use the kernel of a CentOS host.
Containers enjoy the isolation benefits of VMs but is much more portable and efficient.
The containerization is achieved through resource isolation features of linux.
- chroot: change the root directory of a process
- control groups (cgroups): limit the resource (memory, CPU) usage for a group of processes
- namespaces: limit the view of the a process
Containers are efficient because
- faster boot time
- lower memory and disk space footprint
- lower running overhead
In Docker Eco-System,
- dockerfile describes how to build the layered image
- image is a file system and configuration. Images can be shared and run everywhere.
- container is a running instance of image
Compared with VMs, Docker is preferable if you need to deploy the same service in a cluster.